Why Your Strongest Signals Are Losing You Money
The InDecision Engine shipped with a conviction hierarchy that looked textbook-correct. An outcome correlator query overturned it in thirty seconds. The strongest conviction tier had a 49.4% win rate and negative PnL. The weakest directional tier had 75%. The engine was designed backwards.
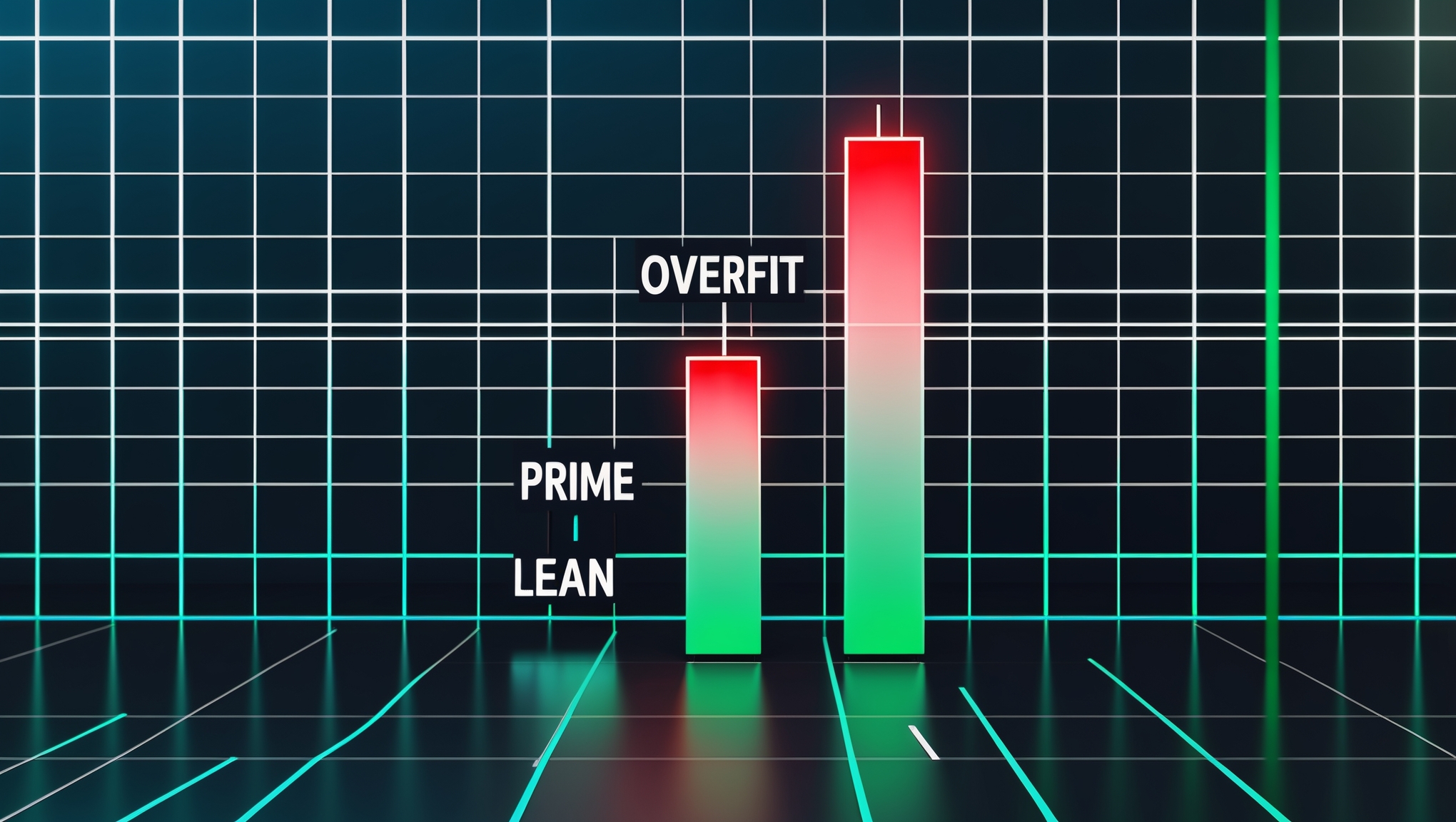
The strongest conviction label in our signal engine had a 49.4% win rate and lost money.
The weakest directional label had a 75% win rate and made money.
The engine was designed backwards. We did not know it was backwards until we ran a single SQL query against stored outcomes. That query was the highest-ROI thirty seconds of the entire engineering session.
The Conviction Architecture We Shipped
When we built the signal engine, we did what most quant systems do: we sorted outputs into conviction tiers. The intuition was the standard one. More confluent signals deserve a higher conviction label. Higher conviction labels deserve more capital. It is the way every trading system I have ever read about tells you to think.
We shipped three tiers:
- OVERFIT — the highest conviction label. Maximum confluence. The signal passed every gate we had.
- PRIME — moderate conviction. Most gates passed. A few softer alignments.
- LEAN — a neutral directional bias. Just enough evidence to take a side.
The assumption baked into the names was that OVERFIT should be the best-performing bucket and LEAN should be the worst. That is the hierarchy the engine was built around. Capital scaling favored OVERFIT. Alerting prioritized OVERFIT. Dashboards ranked OVERFIT at the top.
Then we ran the outcome correlator.
One Query, Everything Upside Down
The query was simple. For every signal the engine had fired, join it against the stored outcome. Group by conviction tier. Compute win rate and PnL per tier. No modeling. No inference. Pure arithmetic against the results we already had on disk.
Here is what came out:
| Tier | Win Rate | PnL |
|---|---|---|
| OVERFIT (strongest conviction) | 49.4% | Negative |
| PRIME (moderate conviction) | 63.9% | Positive |
| LEAN (neutral directional) | 75.0% | Positive |
Read that table twice. The ordering is the opposite of what the engine was built to assume. The strongest conviction tier was a coin flip with negative expectancy. The weakest directional tier was the most profitable category in the system. Everything the engine prioritized was underperforming, and everything it deprioritized was carrying the portfolio.
Why The Strongest Signals Lose
The explanation is not exotic. It is a well-known failure mode that most systems pretend does not apply to them. When a signal passes every gate, every alignment, every confluence check — it usually means the obvious move has been obvious for a while. The consensus has already priced it. By the time your rubric declares maximum conviction, the edge has been absorbed by everyone else who runs a slightly different version of your rubric.
The InDecision Framework treats maximum confluence as a warning, not a green light. This is the same skepticism the broader Jeremy Knox engineering stack applies across every scoring system it runs: counter-consensus signals with moderate confluence tend to have more runway because fewer systems fire on them. A directional lean with no resistance above — the LEAN tier — often catches a move before confluence has had time to accumulate.
This is what the outcome correlator was telling us. The engine was not broken. The engine was calibrated to the wrong definition of quality. It was rewarding the signals that looked most like textbook edge and punishing the signals that actually produced it.
The Action Was Immediate
We did three things the same afternoon:
- Suppressed OVERFIT in production. Signals flagged as OVERFIT stopped triggering trades. They still log. They still get scored. They just do not execute capital anymore. If you cannot fix a tier's PnL, you starve it.
- Promoted PRIME to the capital-scaling head. PRIME became the only tier allowed to scale position size. Its 63.9% win rate plus positive PnL earned it that role.
- Enabled LEAN. LEAN signals had been treated as noise. They went live with fixed position sizing. 75% win rate on lower confluence means they produce the most trades and the most PnL per dollar at risk.
Threshold logic stayed the same. Confluence math stayed the same. Only the labels attached to each bucket changed — and the policy attached to each label. The fix was not code. It was a reclassification of what we were willing to let capital follow.
What We Missed For Months
The painful part of this story is not the finding. It is how long the finding was hiding in plain sight.
The data was already in the database. The component scores were stored. The outcomes were stored. The conviction labels were stored. The correlator was a single query. Nothing prevented us from running it on day one. Nothing prevented us from running it on day thirty. We did not run it because we did not think we needed to. We trusted the conviction hierarchy the same way everyone trusts a system they built themselves.
The lesson here is straightforward and, like most real lessons, deeply uncomfortable: run the outcome correlator before you trust your own labels. Every conviction tier, every confidence score, every probability bucket in your system should have its labels validated against actual outcomes at regular intervals. The engine does not know what its labels mean. Only the outcome can tell you.
If you are running a scoring system with conviction tiers, try this exercise today. Pull every signal in your history. Join it against whatever outcome metric you trust. Group by tier. Compute the win rate. If your strongest tier is not the strongest performer, your hierarchy is inverted, and no amount of weight tuning will fix it until you reassign the labels to match the data.
The counter-intuitive lesson of the InDecision outcome correlator is that the system was never wrong about which signals had the most confluence. It was wrong about what confluence was worth. Those are two entirely different claims. Only one of them is testable without running the outcome correlator. And that is why the correlator run was the single highest-ROI engineering decision of the session — a query we could have run any day for months, and the day we finally ran it overturned the entire architecture.
Explore the Invictus Labs Ecosystem
// FOLLOW THE SIGNAL
Follow the Signal
Stay ahead. Daily crypto intelligence, strategy breakdowns, and market analysis.
Get InDecision Framework Signals Weekly
Every week: market bias readings, conviction scores, and the factor breakdown behind each call.